spark on yarn探讨
每个Spark executor作为一个YARN容器(container)运行。Spark可以使得多个Tasks在同一个容器(container)里面运行。当在YARN上运行Spark作业,每个Spark executor作为一个YARN容器(container)运行。Spark可以使得多个Tasks在同一个容器(container)里面运行。这是个很大的优点注意这里和Hadoop的MapReduce作业不一样,MapReduce作业为每个Task开启不同的JVM来运行。虽然说MapReduce可以通过参数来配置。详见mapreduce.job.jvm.numtasks。从广义上讲,yarn-cluster适用于生产环境;而yarn-client适用于交互和调试,也就是希望快速地看到application的输出。 在我们介绍yarn-cluster和yarn-client的深层次的区别之前,我们先明白一个概念:Application Master。在YARN中,每个Application实例都有一个Application Master进程,它是Application启动的第一个容器。它负责和ResourceManager打交道,并请求资源。获取资源之后告诉NodeManager为其启动container。
yarn-cluster和yarn-client模式的区别
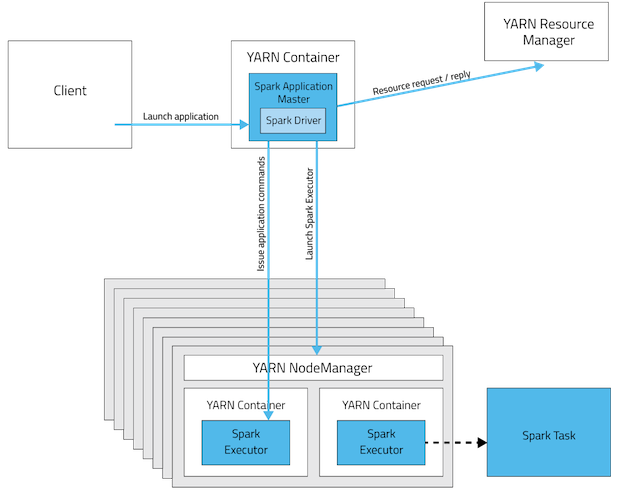
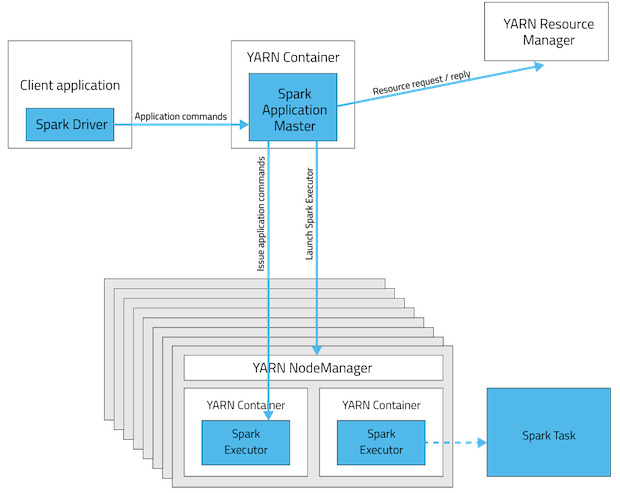
从深层次的含义讲,yarn-cluster和yarn-client模式的区别其实就是Application Master进程的区别,yarn-cluster模式下,driver运行在AM(Application Master)中,它负责向YARN申请资源,并监督作业的运行状况。当用户提交了作业之后,就可以关掉Client,作业会继续在YARN上运行。然而yarn-cluster模式不适合运行交互类型的作业。而yarn-client模式下,Application Master仅仅向YARN请求executor,client会和请求的container通信来调度他们工作,也就是说Client不能离开。看下下面的两幅图应该会明白(上图是yarn-cluster模式,下图是yarn-client模式)
下图给出具体区别:上图是Yarn-cluster模式,下图是Yarn-client模式
对spark而言:Job=多个stage,Stage=多个同种task, Task分为ShuffleMapTask和ResultTask,Dependency分为ShuffleDependency和NarrowDependency
具体图示如下:
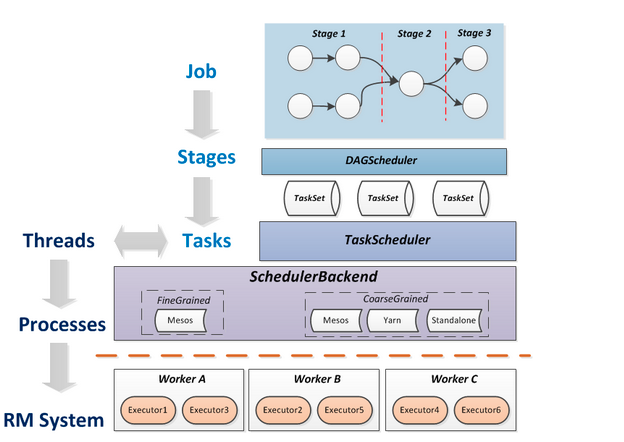
Spark作业当调度执行流程:
- 在使用spark-summit提交spark程序后,根据提交时指定(deploy-mode)的位置,创建driver进程,driver进程根据sparkconf中的配置,初始化sparkcontext。Sparkcontext的启动后,创建DAG Scheduler(将DAG图分解成stage)和Task Scheduler(提交和监控task)两个调度模块。
- driver进程根据配置参数向resource manager(资源管理器)申请资源(主要是用来执行的executor),resource manager接到到了Application的注册请求之后,会使用自己的资源调度算法,在spark集群的worker上,通知worker为application启动多个Executor。
- executor创建后,会向resource manager进行资源及状态反馈,以便resource manager对executor进行状态监控,如监控到有失败的executor,则会立即重新创建。
- Executor会向taskScheduler反向注册,以便获取taskScheduler分配的task
- Driver完成SparkContext初始化,继续执行application程序,当执行到Action时,就会创建Job。并且由DAGScheduler将Job划分多个Stage,每个Stage 由TaskSet 组成,并将TaskSet提交给taskScheduler,taskScheduler把TaskSet中的task依次提交给Executor, Executor在接收到task之后,会使用taskRunner(封装task的线程池)来封装task,然后,从Executor的线程池中取出一个线程来执行task
- 就这样Spark的每个Stage被作为TaskSet提交给Executor执行,每个Task对应一个RDD的partition,执行我们的定义的算子和函数。直到所有操作执行完为止。如下图所示:

Stage的划分不仅根据RDD的依赖关系,还有一个原则是将依赖链断开,每个stage内部可以并行运行,整个作业按照stage顺序依次执行,最终完成整个Job。
为什么Spark将依赖分为窄依赖和宽依赖?
(1) 窄依赖(narrow dependencies)可以支持在同一个集群Executor上,以pipeline管道形式顺序执行多条命令,也就是可以做到同一个分区内的数据局部并行执行例如在执行了map后,紧接着执行filter。分区内的计算收敛,不需要依赖所有分区的数据,可以并行地在不同节点进行计算。所以它的失败恢复也更有效,因为它只需要重新计算丢失的parent partition即可
(2)宽依赖(shuffle dependencies) 则需要所有的父分区都是可用的,必须等RDD的parent partition数据全部ready之后才能开始计算,可能还需要调用类似MapReduce之类的操作进行跨节点传递。从失败恢复的角度看,shuffle dependencies 牵涉RDD各级的多个parent partition。
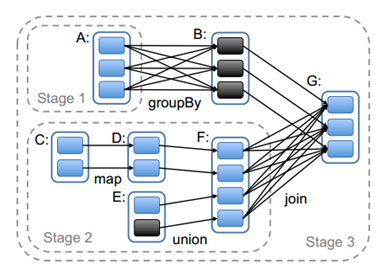
![image]实际划分时,DAGScheduler就是根据DAG图,从图的末端逆向遍历整个依赖链,一般是以一次shuffle为边界来划分的。一般划分stage是从程序执行流程的最后往前划分,遇到宽依赖就断开,遇到窄依赖就将将其加入当前stage中。一个典型的RDD Graph如下图所示:其中实线框是RDD,RDD内的实心矩形是各个分区,实线箭头表示父子分区间依赖关系,虚线框表示stage。针对下图流程首先根据最后一步join(宽依赖)操作来作为划分stage的边界,再往左走,A和B之间有个group by也为宽依赖,也可作为stage划分的边界,所以我们将下图划分为三个stage。